

Yes I may be a weird old tech hoarder but sometimes it comes in handy.
Ok, yes, it’s rare. But when it does, oh how it does!

Yes I may be a weird old tech hoarder but sometimes it comes in handy.
Ok, yes, it’s rare. But when it does, oh how it does!
Due to an ongoing legal dispute over trademark infringement, #Hoarder was forced to change its name.
My go-to tool for collecting all kinds of things from the web is now known as #Karakeep.
https://lemmy.klein.ruhr/post/79159
I wish Mohamed Bassem all the best for the upcoming legal dispute.
Менеджер закладок на своём сервере
Хранить тысячи закладок в браузере — совершенно неблагодарная задача. Там отсутствуют даже офлайн-предпросмотр и автоматические теги, не говоря о полнотекстовом поиске и автоматическом скачивании/архивировании по RSS. Для нормального управления закладками нужно специализированное решение. Тут много вариантов, а одно из лучших — это опенсорсное приложение Hoarder («Копилка информации»). Оно устанавливается на сервер и выступает единой БД для доступа из любых клиентов: Android, iOS, Chrome, Firefox и т. д. Рассмотрим базовые функции этого приложения и как установить его на машине, где хранится личный информационный архив. Это может быть или домашний сервер, или VPS.
Anytype looks very interesting with p2p synchronization! It might replace multiples of software on my side: Obsidian Hoarder, Dayone, and Reminder. A self-hosted solution is available, too!
Are anyone using this solution?
Ps: as always, you can reply in French :-)
#anytype #obsidian #hoarder #dayone #selfhosted
https://doc.anytype.io/anytype-docs/data-and-security/self-hosting/self-hosted
https://social.vivaldi.net/@ueeu/114207916650277992
Weeknote 11/2025: playing with #hoarder and #wallabag, new flooring, fighting #aws lambda functions and setting up #HomeAssistant https://brainsteam.co.uk/2025/3/16/weeknote-11/

What's the suggested solution to get a #selfhosted, easy to use #bookmark sync service? I'll need Chrome, Firefox, iOS Safari to get in sync wrt bookmarks. @wallabag looks nice but I don't want to have those saved pages for later offline stored. I just need to copy the existing bookmark manager structure (folder and links) into something selfhosted and easy to use. #hoarder looks promising but is running AI stuff but has the necessary app extensions. #linkding is quite simple, but only uses tags for management instead of folders. Any ideas or suggestions? #selfhosting
 For Self-Hosters: The "Where Did That Link Go?" Problem
Bluesky is full of great posts - until they vanish into bookmark chaos. #Hoarder keeps them organized, with auto tagging, lists, and even a mobile app + browser extension.
Setup guide: schmetter.link/hoarder
#SelfHosting #Docker #OpenSource
For Self-Hosters: The "Where Did That Link Go?" Problem
Bluesky is full of great posts - until they vanish into bookmark chaos. #Hoarder keeps them organized, with auto tagging, lists, and even a mobile app + browser extension.
Setup guide: schmetter.link/hoarder
#SelfHosting #Docker #OpenSource
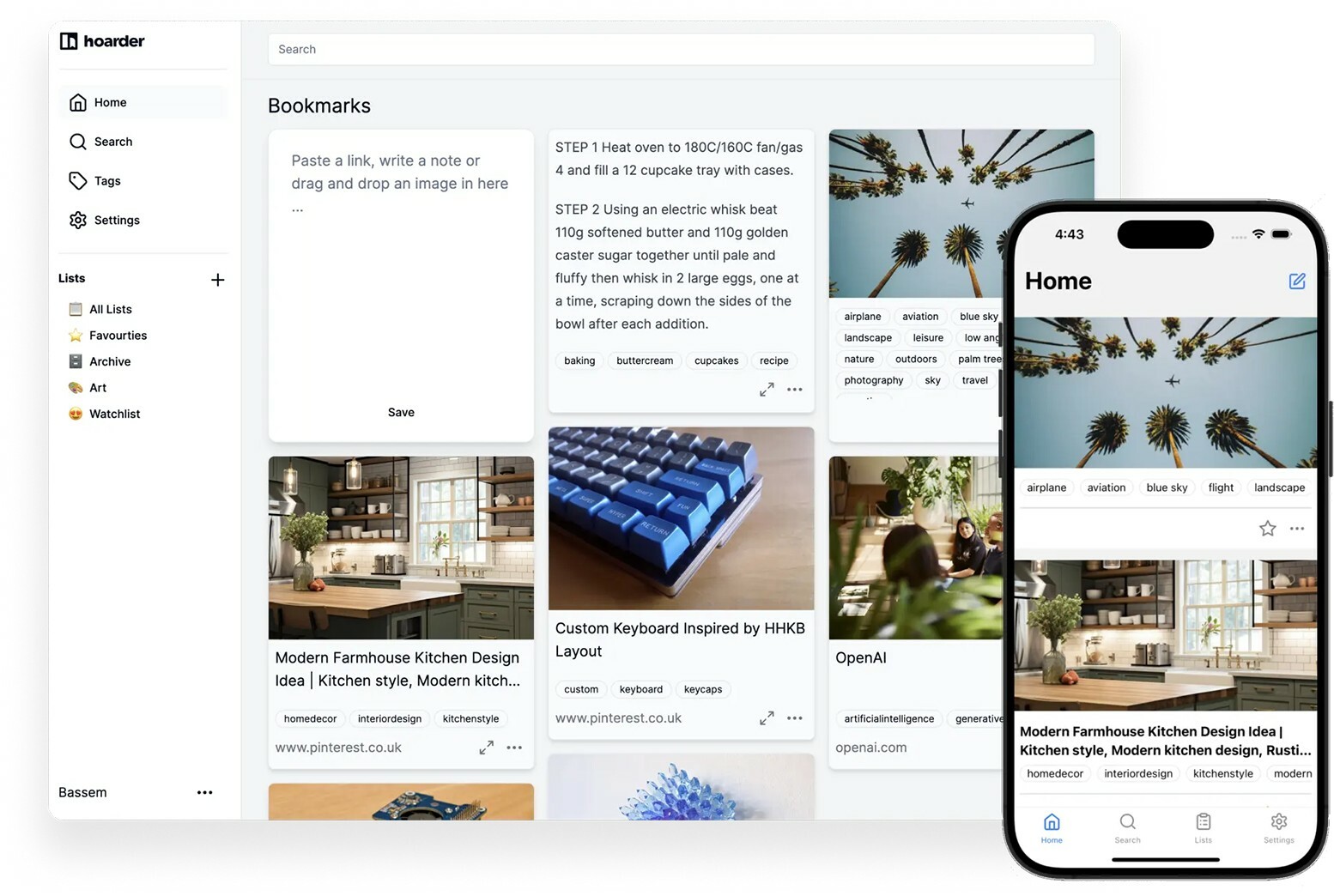
Bookmark Management with Hoard...
Any #selfhosted bookmarking app suggestions ? I had used #wallabag back then, but it was a long time ago, and there are some new apps on the street such as #linkwarden or #hoarder . What link bookmarking / archiving apps are you using, and why?
So I've been using Hoarder in my #homelab for a month.
It's a self-hosted bookmarking service that makes offline copies (text + screenshot) of whatever you save in there. It has great features like lists for easy content organization, RSS feed fetching, AI summarization and tagging, and much much more.
I'm using it to store web articles offline and as a read-it-later service, all self-hosted and easy to deploy with Docker. Quite happy with it so far.
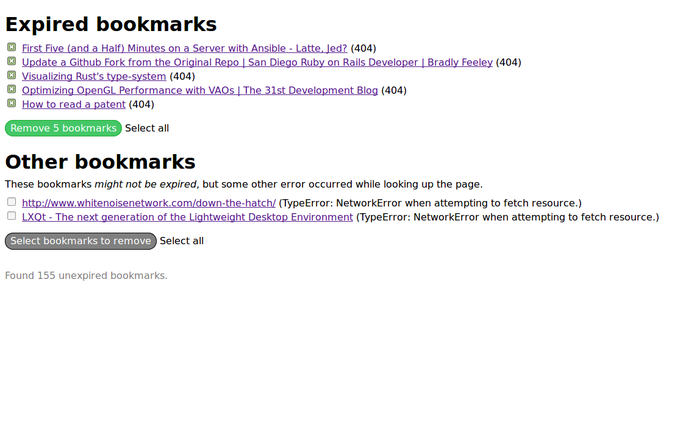
I personally have probably a couple thousand bookmarks, and this #Firefox #Addon by @evilpie helps filter out inactive links:
https://addons.mozilla.org/en-US/firefox/addon/404-bookmarks/
It would be great to auto-check the archive sites for backup links, export as txt etc. But hey, the code is #FOSS!
Any #Selfhosted #Hoarder app users have this issue? I'm seeing that Hoarder is struggling to capture any Mastodon posts, some people have some great info in threads that they haven't posted on blogs and I want to save the references.
Do you have any config tweaks you'd suggest? I already turned on CRAWLER_FULL_PAGE_ARCHIVE and CRAWLER_FULL_PAGE_ARCHIVE to true. I'm not getting full screenshots for any pages but getting page archives for "normal websites" but neither for Mastodon posts. I'd appreciate any pointers!
Bought a new house and now I am packing up all my gadgets, cables, electronic components......damn! I have gathered a small shop full of stuff over the years.
Will take some time to sort through all of this in my new workshop.
#1000projects #gadgets #hoarder #movingout
I've been using a great knowledge management tool called Hoarder. https://hoarder.app/ I makes it easy to bookmark urls, notes and images, retrieves thumbnails and does auto-tagging via the LLM of your choice.
The next version will implement webhooks allow external tools to get notified of new bookmarks. I'm thinking of using this to create an #activitypub bot that publishes a stream of my bookmarks together with my notes.
The ultimate goal would be to create a #federated knowledge management system where I can subscribe to other people's feeds and vice versa.
Is this a good idea? Is anyone interested?
#hoarder #obsidian #llms
"Welcome to the 0.22.0 release of Hoarder! This is a lightweight release given the recent events. This release introduces Webhook support, SingleFile support, bookmark sorting, and a lot of fixes!"

Now I'm having #linkwarden and #hoarder running.
And I like both of those apps. Linkwarden is more straight to the point and feels a little bit more organized. Hoarder got the blink going on, the AI tagging works quite well (I've still a few $ laying around in my OpenAI api wallet) and it can work as a #keep alternative.
Decisions, decisions. I don't think I'll work with both in the long run.
Something if you're bored.
HOARDER project (https://github.com/hoarder-app/hoarder) recieved a Cease and desist from a company behind HORDR mobile app, due to "copyright infringement".
Hordr claimed, that Hoarder stole their name, even tho at the time of sending CaD they didn't even release the app.
Yeah... Yeah... I just can't...
 with AI-based automatic tagging and full text search - hoarder-app/hoarder")
I've been off of #Facebook since February of 2020 (weird unconscious foresight. I got lucky). I've only recently just pulled down all of my #data. Photos, videos, etc. And yet I still can't bring myself to log in and delete the account for good. Why is that? What's that about? Is that just my #hoarder tendencies? Do I not trust that I have everything downloaded? I have no intention of ever actually using the service again but for some reason haven't pushed the big red button yet. I don't get it.
I'm still on the hunt for a good self-hosted link manager. #Goodlinks is okay, but only on IOS and mac, not windows. #linkwarden uses hover for, like, everything, making it almost completely inaccessible. #Hoarder has basically no labeled buttons or links. I want something that's #accessible, cross-platform, #selfhosted, will archive pages, and offers full-text search. Three quarters of the time when I use Google, I'm just searching for something I already know about. In an ideal world, a selfhosted link/bookmark manager would reduce my dependence on big-tech search engines. Maybe #archivebox? But that looks like it's more about storing the data than actually doing anything useful with it like search or tagging or whatever. #a11y

 |
|




























