

Streamlining access to tabular datasets stored in Amazon S3 Tables with DuckDB | AWS Storage Blog

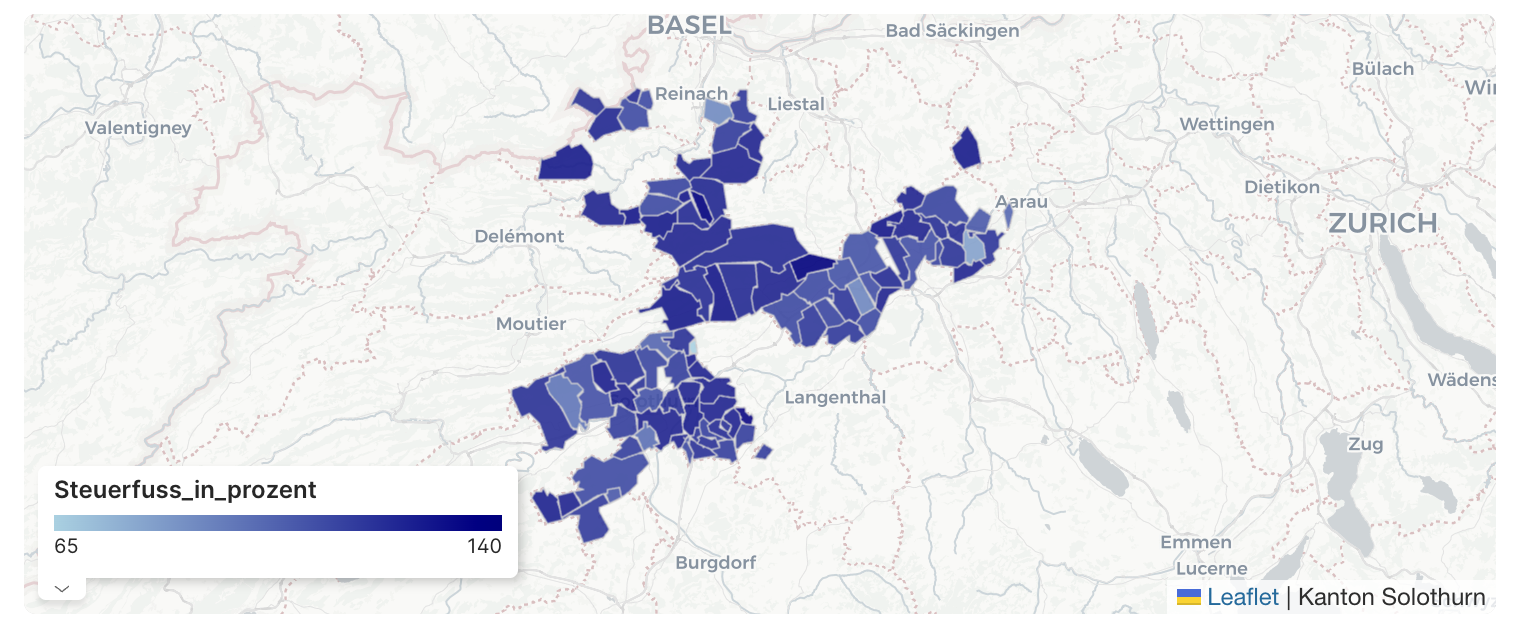
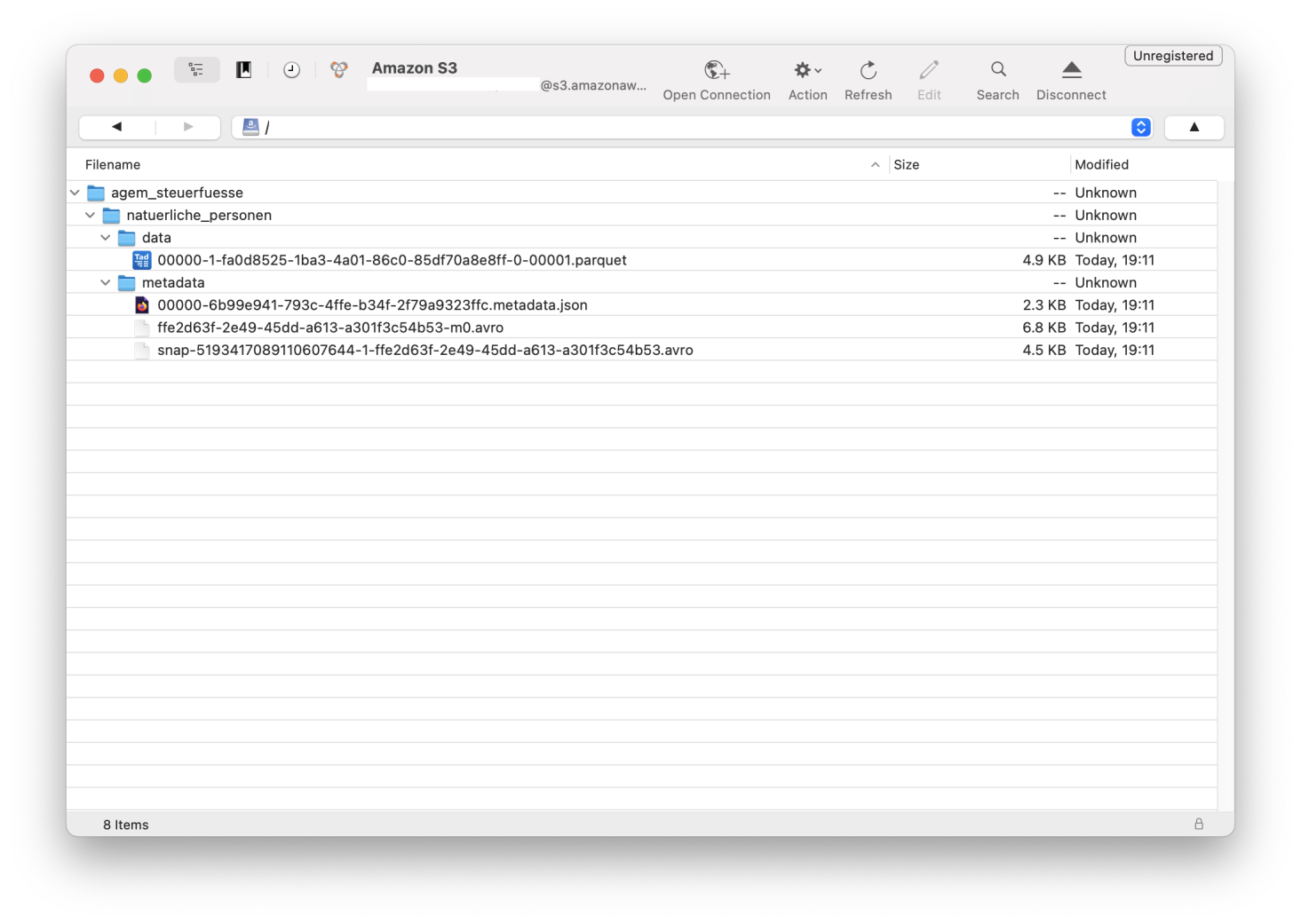
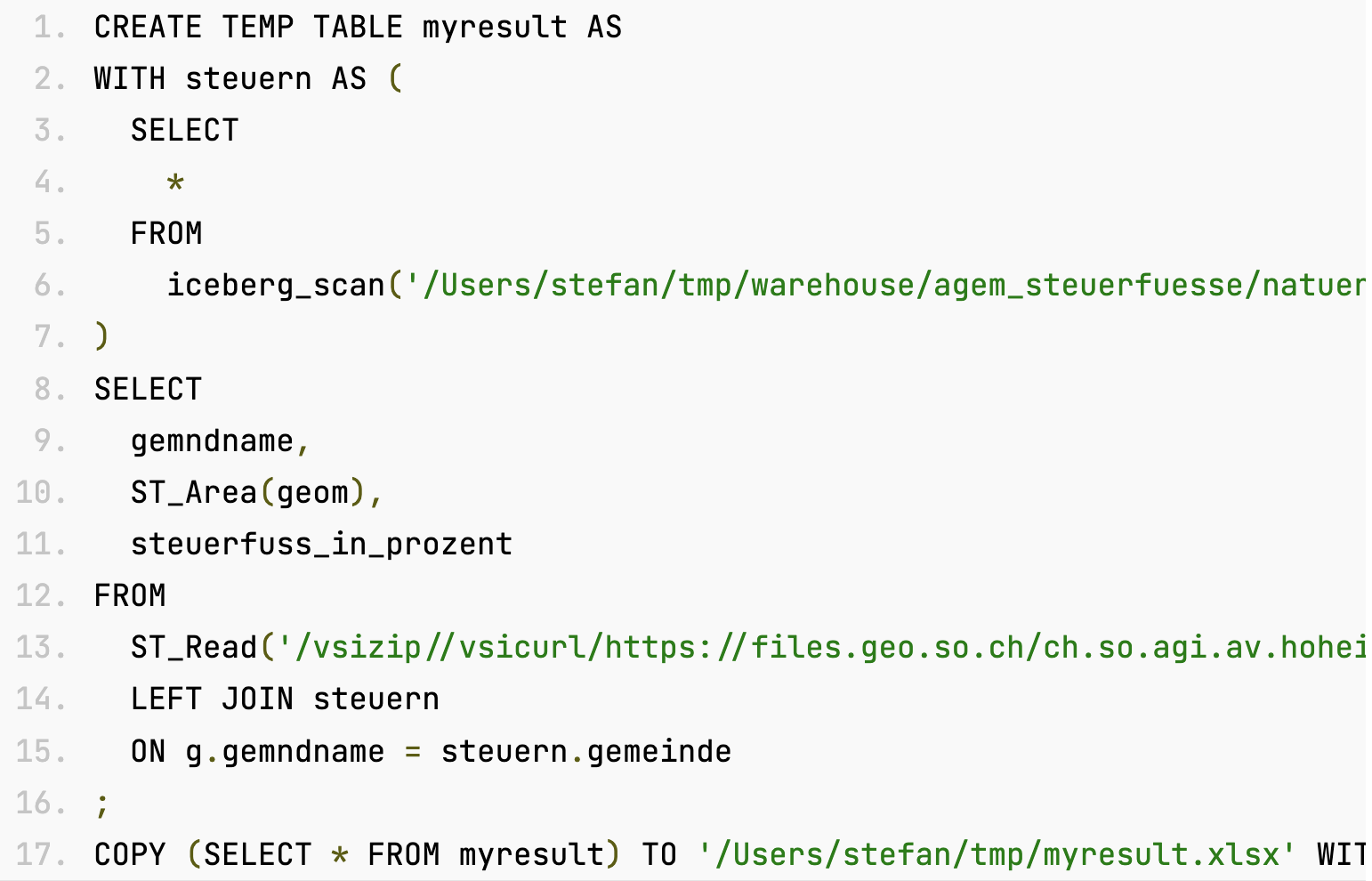
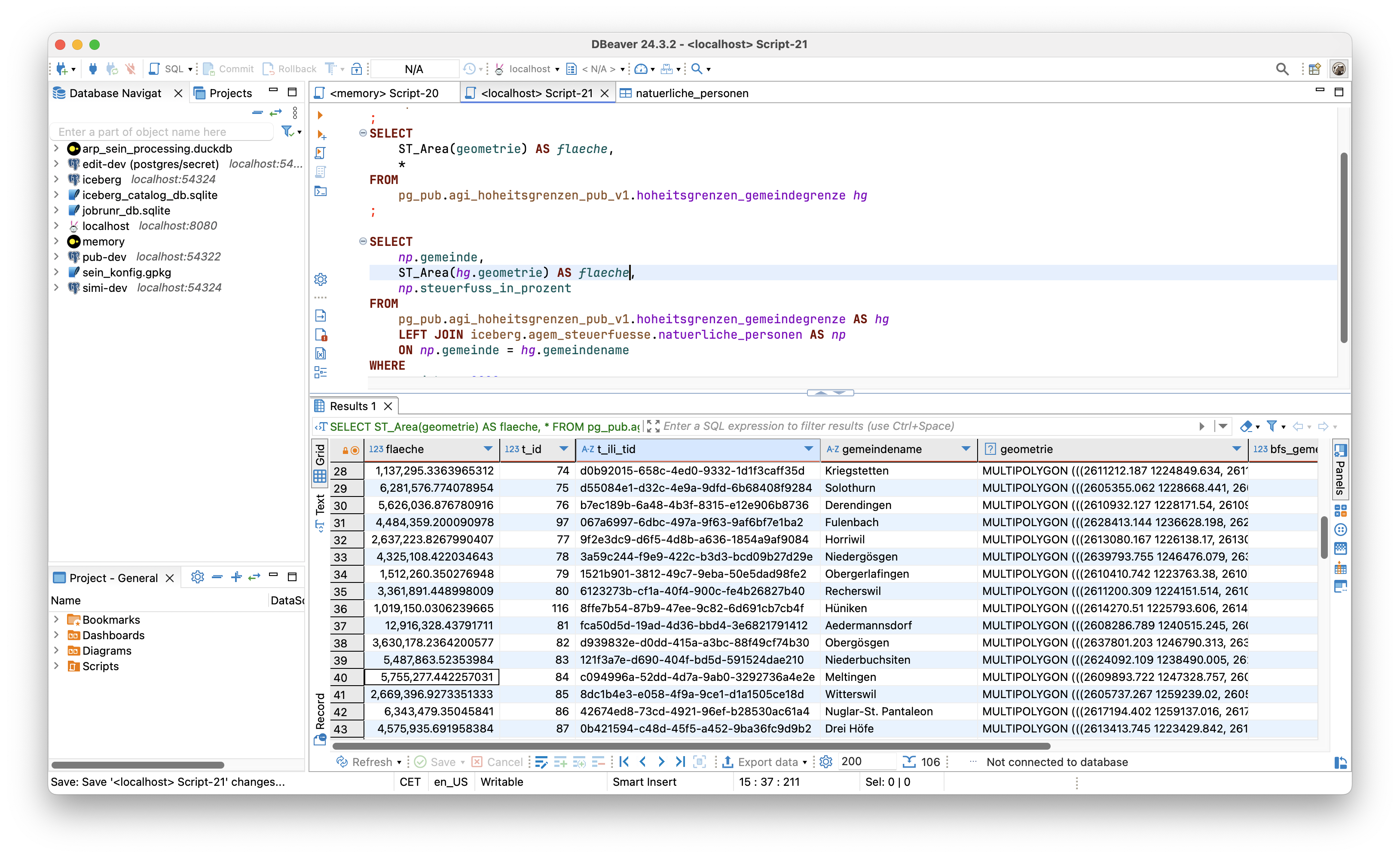
Amazon Web Services · Streamlining access to tabular datasets stored in Amazon S3 Tables with DuckDB | Amazon Web ServicesAs businesses continue to rely on data-driven decision-making, there’s an increasing demand for tools that streamline and accelerate the process of data analysis. Efficiency and simplicity in application architecture can serve as a competitive edge when driving high-stakes decisions. Developers are seeking lightweight, flexible tools that seamlessly integrate with their existing application stack, specifically solutions […]










 Qiita - 人気の記事
Qiita - 人気の記事 







 The October issue of
The October issue of 


 @ Dremio
@ Dremio 



 ** Here be Dragons^H^H Stacktraces — Flink SQL for Non-Java Developers**
** Here be Dragons^H^H Stacktraces — Flink SQL for Non-Java Developers** Tue Mar 19*
Tue Mar 19* 3:30 PM*
3:30 PM* Breakout room 2*
Breakout room 2*